Paper Study - Homa A Receiver-Driven Low-Latency Transport Protocol Using Network Priorities
10 Feb 2020** This is a study & review of the Homa: A Receiver-Driven Low-Latency Transport Protocol Using Network Priorities paper. I’m not an author.
Homa: A Receiver-Driven Low-Latency Transport Protocol Using Network Priorities
Introduction
- Homa: a new transport protocol designed for small messages in low-latency datacenter environments.
- 99% round trip latencies <= 15 μs for small messages at 80% network load with 10 Gbps link speeds (also improves large messages)
- Priority queues
- Assigns priorities dynamically on receivers
- Integrates the priorities with receiver-driven flow control mechanism similar to pHost, and NDP
- Controlled over-commitment
- Receiver allows a few senders to transmit simultaneously
- Slight over-commitment -> bandwidth efficiency ↑
- Sustain 2-33% higher network loads than qFabric, PIAS, pHost, NDP
- Message-based architecture, not streaming -> reduce head-of-line blocking, 100x over streaming like TCP
- Connectionless -> few connection state in large applications
- No explicit acknowledgements -> reduce overhead for small messages
- At-least-once semantics, not at-most-once
Motivations & Key Ideas
- Low latency hardware popular
- Most of the traffic in datacenter are less than 1000 bytes (70%-80%), aka small messages.
- But existing transport designs cannot achieve lowest possible latency for small messages.
- Challenges & solutions
- Eliminate queuing delays, worst-case: incast
- Potential solution: schedule every packet at a central arbiter, Fastpass.
- Cons: need to wait for scheduling decision, 1.5x RTT.
- Homa: transmit short messages blindly (without considering congestions) to cover the half RTT( to the receiver), RTTBytes = 10KB in 10 Gbps network
- Buffering, inevitable
- Potential solutions: rate control, reserve bandwidth headroom, limit buffer size
- Cons: cannot eliminate penalty of buffering
- Homa: use in-network priorities. Short messages processed before large messages. SPRT (shortest remaining processing time first) policy
- qFabric: too many priority levels for today’s switches. PIAS: assign priorities on sender, limi approximation of SRPT. QJUMP: manual assignment of priorities, inflexible.
- Priorities must be controlled by the receiver, because receiver have more information on the downlink (bandwidth, set of messages…) so that the receiver can best decide priority for incoming packet.
- Receivers must allocate priorities dynamically,
- Large message: priority based on exact set of inbound messages -> eliminates preemption lag.
- Small message: provide guidance (priority) based on recent work-load.
- Receivers must overcommit their downlink in a controlled manner.
- Scheduling transmission with grants from receiver -> multiple grants simultaneously -> sender need time to process -> hurt performance, max load pHost 58%-73%
- Overcommit: allowing small set of senders send simultaneously.
- Sender uses SRPT also
- Eliminate queuing delays, worst-case: incast
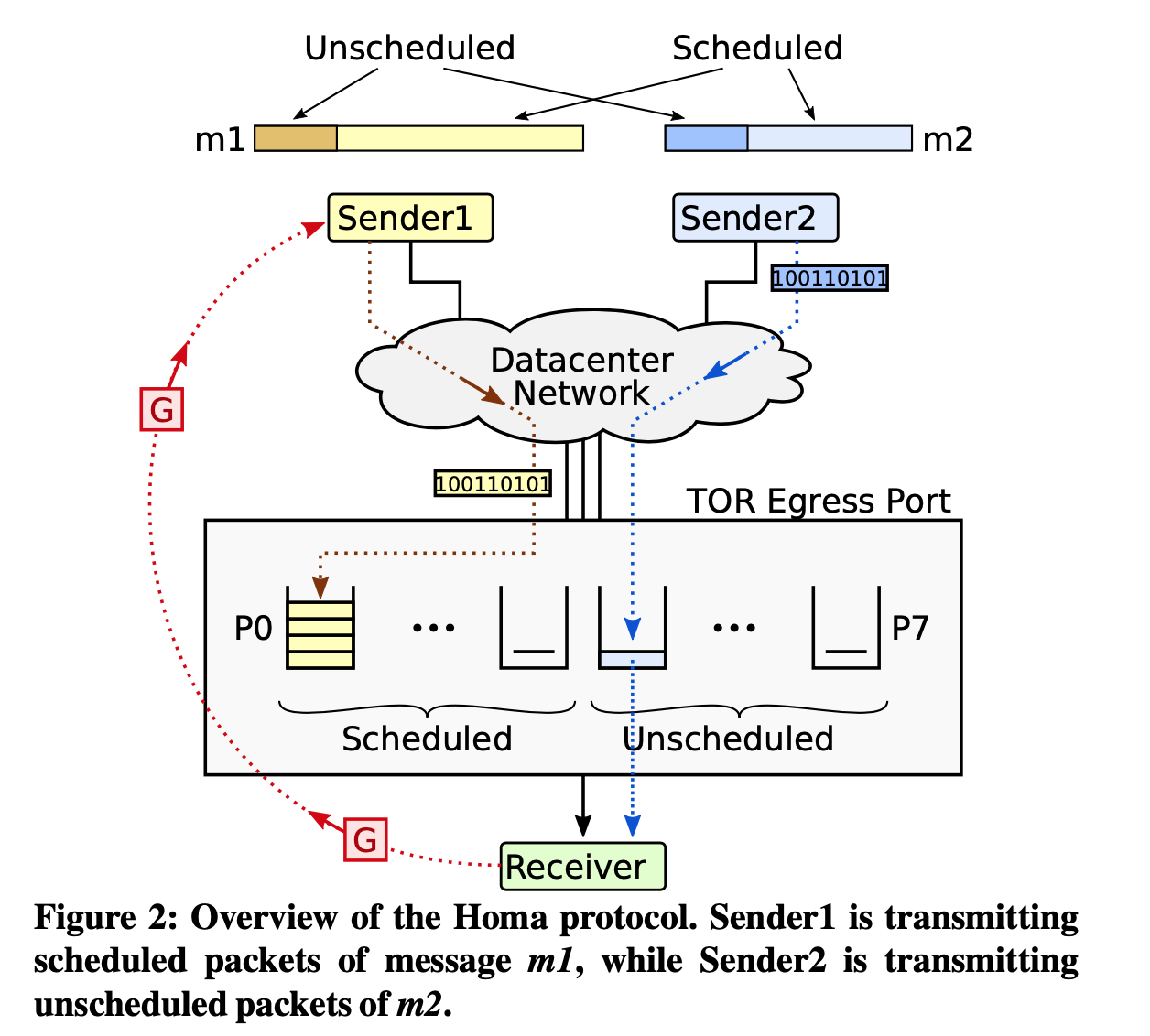
- Unscheduled: RTTBytes, blindly.
- Schedule: wait for receiver response.
- G: grant packet: acknowledge receipt with priority
Designs
-

-
Priorities
-
Unscheduled packet
- Use recent traffic patterns
- Piggyback on other packets when receiver need to communicate with sender
- $\frac{unscheduled\ bytes}{all\ bytes}$ , for example 80%
- Allocate highest priorities for unscheduled packets (7 out of 8 for 80%).
- Choose cutoffs between unscheduled priorities, so that each priority level is used for an equal amount of unscheduled bytes and shorter messages uses higher priorities.
-
Scheduled packet
- Receiver specify priority and granted bytes in GRANT packet.
- Use low priorities when message amount less than scheduled priorities, reserving higher priorities to avoid preemption lags.
-
-
Overcommitment
- A receiver grant to more than one sender at a time: take advantage of free bandwidth for unresponsive senders
- If some senders unresponsive: take free bandwidth. If all senders responsive, priority ensures short messages arrive first, and buffering in TOR switch.
- Degree of Overcommitment: max number of active messages at once at a receiver.
- $DoV = #\ of scheduled\ priority\ levels$ , one message per priority level
-
Incast
- Counting outstanding RPCs to detect impending incast, mark new RPCs with special flags, and use lower limit for unscheduled bytes
- Because of Homa’s low latency design, and future deployment of low=latency environments (hardware + software), incast is largely rare
-
Loss Detection
- Lost is rare in Home
- Lost of packets is detected by receiver, send RESEND after timeout identifying first missing bytes range.
Eval
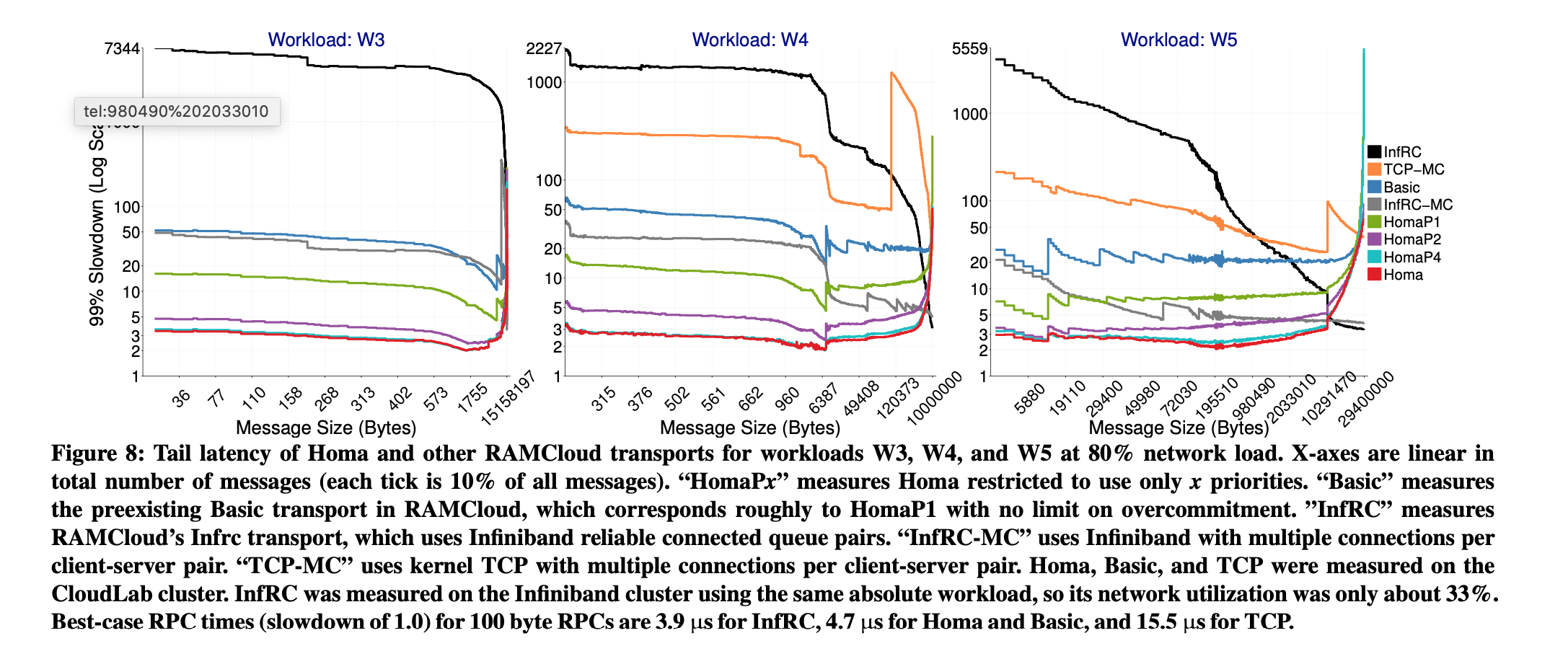
- Great for processing small messages, also performs good with large messages.
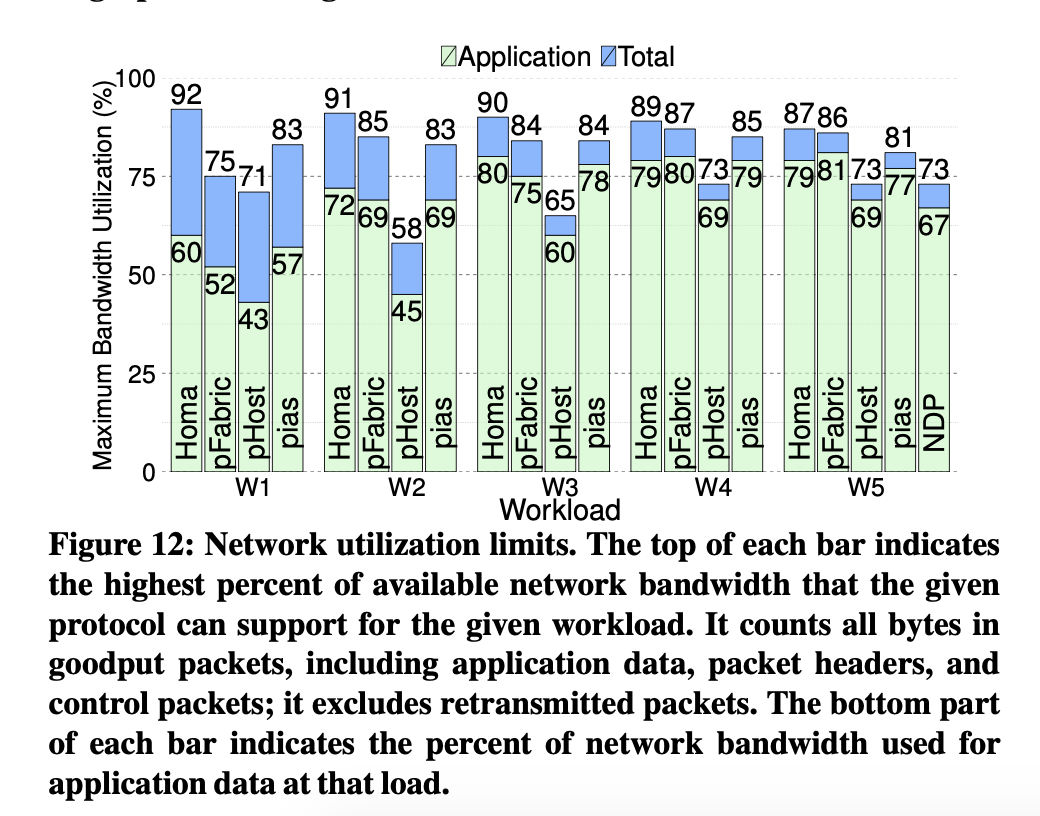
- Network utilization is high
- More comparisons to other protocols, refer to the paper.
Conclusion
∙ It implements discrete messages for remote procedure calls, not byte streams.
∙ It uses in-network priority queues with a hybrid allocation mechanism that approximates SRPT.
∙ It manages most of the protocol from the receiver, not the sender.
∙ It overcommits receiver downlinks in order to maximize throughput at high network loads.
∙ It is connectionless and has no explicit acknowledgments.